Scientific and Technological Achievement Sharing] Diabetes Risk Prediction: Big Data Mining by Integrating Various Physical Examination Indicators—Lin Hao's Research Group from University of Electronic Science and Technology of China, and Tang Hua's Research Group from Southwest Medical University
Recently, the research group of Lin Hao from the University of Electronic Science and Technology of China, the research group of Tang Hua from Southwest Medical University, and Sichuan Black Horse Digital Technology Co., Ltd. have jointly developed a diabetes risk assessment system based on physical examination data. They have published a paper titled "Risk Prediction of Diabetes: Big Data Mining with Fusion of Multifarious Physical Examination Indicators" in the top journal "Information Fusion" in the field of computer science.
Diabetes is currently considered a global chronic disease. Chronically high blood sugar can lead to chronic damage to various tissues. Therefore, early detection and intervention of diabetes are key to preventing diabetes or delaying the onset of diabetes complications. However, due to the limitations of personal economic conditions and limited understanding of their own health status, only half of the diabetic patients are diagnosed at present. With the massive growth of physical examination data and the rapid development of artificial intelligence technology, researchers hope to use physical examination data to establish diabetes risk assessment to provide potential help for clinical guidance and early large-scale screening.
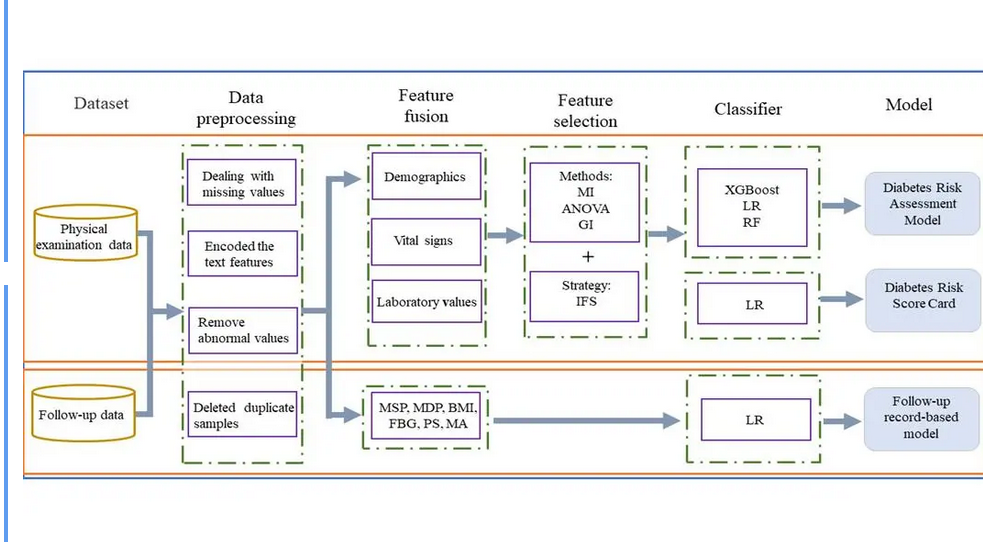
In this work, the diabetes risk assessment system developed by the researchers can assess the risk of diabetes at different levels of cascade. The diabetes risk assessment model is used for systematic screening at the system level. The model can be directly applied to the physical examination information decision-making system in various regions. During the annual physical examination survey, high-risk groups for diabetes can be screened in advance according to the risk score, and preventive control can be carried out to achieve early detection, early prevention, and early treatment of diabetes, thereby reducing the medical insurance costs of the country and various regions. The diabetes risk scoring card quantifies each risk factor in the model and can be directly applied to the clinic, facilitating high-risk groups to understand their own health status and formulate reasonable life plans. The follow-up satisfaction model is used to explore the key factors of diabetic patients' satisfaction with disease control, which can be used for the disease management of diabetic patients.
This study is based on 285,965 diabetic samples and 1,221,598 healthy person samples in the physical examination system of Luzhou City from 2011 to 2017. Clinical features include three major categories: demographic characteristics, vital signs, and laboratory indicator values, totaling 16 items. In clinical application, due to the limitation of collected data, the best prediction effect is hoped to be achieved with the smallest subset of features. Therefore, researchers use three methods: mutual information (MI), analysis of variance (ANOVA), and Gini impurity (GI) to rank the features, then combine the incremental feature selection strategy (IFS) with XGBoost to determine a set of optimal feature subsets. This set of optimal feature subsets includes six features (fasting blood glucose (FBG), mean systolic pressure (MSP), age, waist-to-height ratio (WHtR), body mass index (BMI), and urinary glucose (UGLU)). A diabetes risk assessment model is constructed on this feature subset, and the AUC result on the test set is 0.8763.
To improve the convenience of clinical application, researchers further designed a diabetes risk scoring card. The six features used in the diabetes risk scoring card are the same as those in the diabetes risk assessment model. In the scoring card, researchers first discretize continuous variables through binning, allowing people with different risk levels to correspond to different scores, so that users can score according to their own indicators. The binning method used in the article is equal-frequency binning. The authors use the weight of evidence (WoE) to measure the probability of disease in each bin, map the weight of evidence back to the original dataset, and then use logistic regression to build a model. At this time, the model AUC value is 0.8681. Compared with the diabetes risk assessment model, the model shows a relatively small performance loss, indicating that binning causes little loss to the model and the binning method is reasonable. The authors then combined the model's "coef" parameter with the scoring algorithm to create a scoring card with a score range of 0 - 100 points. The scoring card consists of a base score and the score corresponding to each feature. For every 4.5 points increase in the total score, the risk doubles.
When using the scoring card, add the base score to the score of the corresponding feature to get the total score, and then according to the following table, you can find out the risk range corresponding to the total score.
Based on the follow-up data of the Luzhou City population, researchers have established a follow-up satisfaction model to observe the impact of systolic pressure (SP), diastolic pressure (DP), body mass index (BMI), fasting blood glucose (FBG), psychological state (PS), and medication adherence (MA) on patients' disease control. Researchers found that fasting blood glucose has the greatest impact on patient control satisfaction. Patients with high fasting blood glucose have considerable difficulty in controlling the disease, which is consistent with the actual situation. The higher the blood sugar, the more difficult it is to control the disease, thus affecting satisfaction. It also indirectly illustrates the importance of early diagnosis of diabetes. Medication dependency is also the most important factor in controlling diabetes, indicating that diabetic patients should use medication reasonably and in a timely manner.
This study uses artificial intelligence technology for mining and modeling of massive real diabetes physical examination data, and proposes to use a cascading method to build a diabetes risk assessment system, hoping to provide help for early screening of diabetes.
Article link: https://doi.org/10.1016/j.inffus.2021.02.015
Introduction to Lin Hao's Team
University of Electronic Science and Technology of China— Lin Hao's Team

Engaged in bioinformatics research for a long time
In response to the characteristics of biological macromolecular data, various computational methods have been developed and applied for innovative research on genomic functional elements, RNA localization and modification, and identification of protein structure and function. More than 50 bioinformatics scientific service websites have been established to serve researchers from more than 80 countries and regions. The team has published more than 160 SCI papers in journals such as Information Fusion, Nucleic Acids Research, Briefings in Bioinformatics, and Bioinformatics. These works have been cited more than 6,000 times by international journal SCI. The team has been funded by the National Natural Science Foundation of China, the Youth Project, the National Key R&D Plan, the Sichuan Province Outstanding Youth Fund, and the Sichuan Province Basic Research Program. It has won the Clarivate Highly Cited Researchers Global (2018), the Hebei Province Science and Technology Progress Third Prize (2015), and the Sichuan Province Science and Technology Progress Third Prize (2012). It has been selected as a candidate for the Sichuan Province Science and Technology Leader (2019). (Team website: http://lin-group.cn)